Cookoff: Same Spec, Different Code
← All PostsNo plan survives contact with the enemy. Everyone has a plan until they get punched in the face. Pick your favorite version… the point is the same. Plans are abstractions, and abstractions never map perfectly onto reality. By definition, they admit multiple valid implementations.
But AI makes this harder to ignore, because now that gap between “clear spec” and “correct implementation” can produce genuinely different implementations in the time it used to take to produce one version. If you only ever look at the first “correct” implementation, you may be leaving useful information on the table.
What happens if we explore that space instead of collapsing it immediately?
I wrote Cookoff to lean into that idea and use model variance as a feature.

The setup is straightforward. Same design doc. Multiple agents. Isolated environments. Parallel builds. Then we judge what comes back.
The judging is not just “which one works.” It is “what did each one optimize for?” What assumptions got baked in? What defensive moves appeared in one version but not another? Which solution is simpler in the right way and which one is merely thinner?
We used cookoff to build the TUI for a chat client using Bubble Tea. Three agents got the same spec. Three agents built against the same framework. What came back was not noise. It was a small map of the implementation space.
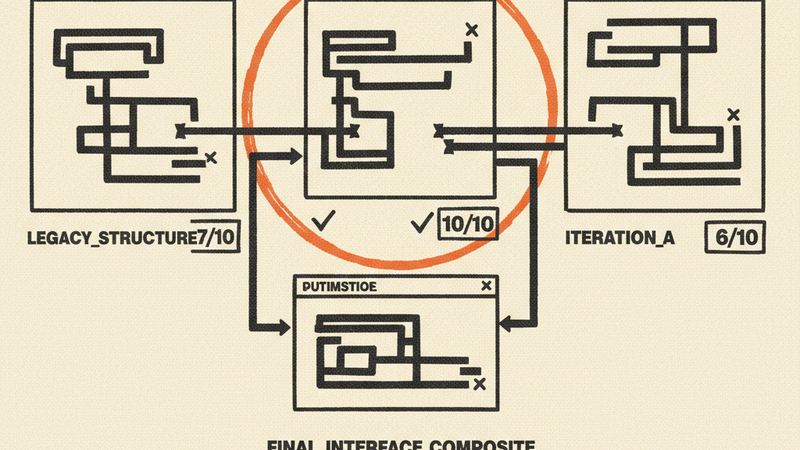
One version used raw HTTP and a flatter model. Another leaned into nested composable models and included a bunch of defensive patterns: cursor clamping, sender fallback logic, timestamp guards, and other quality-of-life hardening. The judge scored the results. They tied at 18 out of 25.
That tie is part of why I like this pattern. There is no empirical “best” implementation. There is best fit, best for now, best given these constraints. Treating implementation as a search for the one correct answer misses the point. The useful outcome is often that multiple approaches are defensible for different reasons, and the real value comes from learning across them into an amalgam that is best in this context.
In this case, the tiebreaker favored the simpler implementation on test count and fewer production lines. Great. That version became the winner. But the “losing” implementation had defensive patterns the winner lacked. A paste race-condition fix. UTF-8-safe truncation. A zero-timestamp guard.
So we stole those ideas.
That is the actual payoff. Cookoff is not merely a way to crown a champion. It is a way to learn from divergence before you collapse back to one codebase. The final result can be better than any single candidate because you are not forced to accept the accidental bundling that came with one agent’s choices.
In this instance we ported the strongest defensive patterns back into the simpler winner and ended up with final code that was better than either implementation in isolation.
That is a meaningful shift in how I think about nondeterminism. If you only want one answer, nondeterminism looks like a problem to suppress. If you can compare outputs intelligently, and thrive in the nuance, nondeterminism becomes exploration.
There is a cost, obviously. Running multiple implementations is more expensive than running one. But when you bring ideas back from the “losing” runs, you recoup that cost by not having to address those shortcomings from scratch later. Or worse, by not having to address them after they fail in production. The comparison cost is worth paying precisely when the implementation details matter and when the shape of failure is hard to predict up front.
It also changes how wrongness feels. If one implementation falls over, you are not back at zero. You have already bought more of the search space. You know what else was tried. You may already have a backup path in hand. That is not just useful for quality. It is useful for momentum.
Not all uncertainty is front-loaded. Some of it survives clear direction. Some of it only appears once real code gets written. Cookoff is for that layer. It gives me implementations to compare in the same way Omakase gives me artifacts to react to and Deliberation gives me perspectives to think alongside.
Same theme, different object of reaction.
I do not want AI coding systems that merely hide variance from me and return the first thing that compiles. I want systems that let me inspect meaningful differences when those differences matter. Sometimes the winner is the answer. Sometimes the spread between answers is the answer.
Try it
Cookoff is part of the Test Kitchen plugin for Claude Code.
/plugin marketplace add 2389-research/claude-plugins
/plugin install test-kitchen