Simmer: A Self Honing Skill
← All PostsA Berkeley paper showed that you can apply RL-style feedback loops to any text task as long as you can evaluate the output and give prioritized, actionable feedback. They call it Actionable Side Information (ASI). The goal is feedback focused on what to improve next. For an API that might be “the POST endpoint has no error responses.” For a story, “the pacing drops in paragraph two.” Focused enough that the generator can act on it without scattering.

We built this as a Claude Code skill called simmer. You define what you are refining and the criteria for “better.” The agent generates, judges against those criteria, feeds the prioritized fixes back, and repeats. Works on anything text-shaped. Adventure hooks, pitch emails, API specs, blog posts.
Then we tested simmer by using it to hone itself using a simple inner/outer agentic loop. The outer loop: take a version of the skill definition, evaluate how well it performs, find the breakpoints, improve the skill, repeat. For each version, the inner loop: spin up three agents with that skill definition and a set of test tasks, let each agent simmer those tasks independently, compare the results. Three outer iterations. Here is what that taught us.

Judges need calibration or they inflate
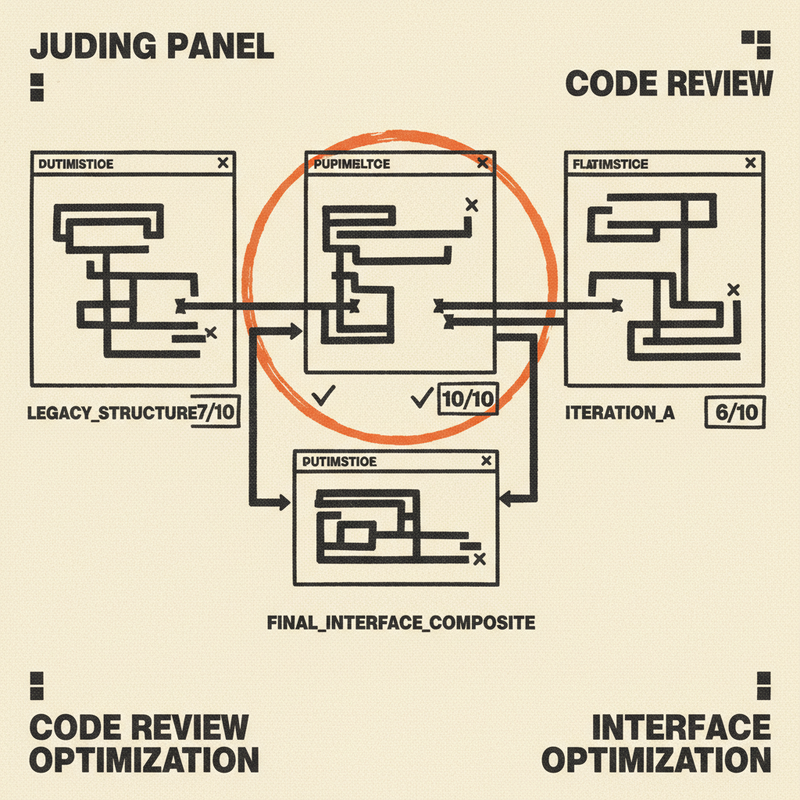
First inner run, I pulled up the score trajectories and every single one scored 9.2 which looked great until I read the actual text. Without extremely specific criteria the judges in each subagent were inflating scores, for example the round-three adventure hook still had a passive villain and no stakes which doesn’t make for a compelling DnD adventure module.
The judge was drifting toward generous scores because it had no memory of where it started or what the scores meant. The fix was giving the judge the seed artifact and its iteration-0 scores as permanent context every round, plus explicit anchors for what each score level means. Once we added that, scoring became consistent and more directionally correct across runs.
The skill improved faster than the artifacts did
The inner loop results got better across outer iterations, but not because the artifacts changed dramatically. The adventure hooks and API specs were genuinely good from run one. The main improvement in the skill over time was that the iterations helped determine which instructions that felt clear to us were ambiguous to agents. “Default 3 iterations” produced three different iteration counts. “Record a trajectory” produced three different table schemas. The fix was always the same: replace the instruction with an explicit contract. By the third outer pass, all three agents in the inner loop followed the same process, produced comparable scores, and hit similar quality levels independently. Letting simmer hone itself in this experimental loop made it much more specific and focused which made running subagents and executing the full pipeline more consistent over time.
Why this works
In traditional ML, feedback loops mean random walks through a latent space over thousands of iterations to approximate a solution. With our agents we don’t have to do this, the backbone LLMs start from massive pretrained competence and a solid understanding of most topics. The model already knows what a good API spec looks like, what a compelling adventure hook reads like. It does not need to search from scratch. It needs someone to point out what is missing from this specific artifact. That is what makes the ASI mechanism practical. Pointed feedback plus a capable agent means you converge in three to five rounds instead of three thousand.
Try it
Simmer is part of the Test Kitchen plugin for Claude Code.
/plugin marketplace add 2389-research/claude-plugins
/plugin install simmer