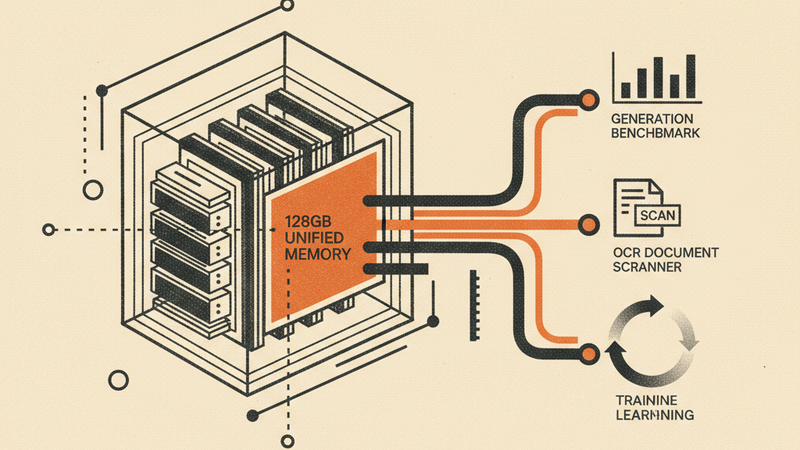
One day I came into work and Harper (our
CEO) asked me something along the lines of “What can we do
with this NVIDIA Spark box?” I had no idea what it was since it hadn’t been
released yet. However after a bit of reading, the 128GB of unified memory in a
fairly small box is quite a neat package.It is very very gold and shiny
As a data scientist a lot of my time over the past decade has been training
neural networks and one of the major constraints has been GPU RAM. This ranges
from the old 1070/1080 cards up through a personal 4090 and the industry cards
like A10s and a H100 at one point. While most common tasks are still very doable
on an H100, having access to the 128GB from the NVIDIA box and having it in
house is quite novel. In order to see how the Spark box did, I decided I would
do a few different tests 1. Run a Llama
4 model via
Ollama for text generation tasks, benchmark
this vs my M4 Apple Silicon Mac with 128GB of RAM 2. Configure it to run a new
DeepSeek OCR model 3. Train a
LoRA adapter for a Llama 3.1 70B model I figured that this was a reasonable
collection of tasks ranging from more basic standard pipelines like generation
to getting a new model working which would involve more troubleshooting
compatibility issues, and finally doing a training run with a reasonably large
model that for the most part has been out of my standard ability to train. ##
“Hello World” running Llama 4 on NVIDIA Spark After getting my connection setup
and some very basic familiarity with the system I decided to try and pull down a
Llama 4 models from
meta and see some basic text generation with it. Installing and running Ollama
and OpenWebGUI was a pretty quick process since the pipeline is well documented
and understood, it took maybe 60 minutes where most of it was just downloading
the Llama 4 model multiple times due to errors on my part. I selected the Llama
4 Scout model which has 109B parameters where it only has a smaller 17B
parameter subset active at any given time. I downloaded the model and when I ran
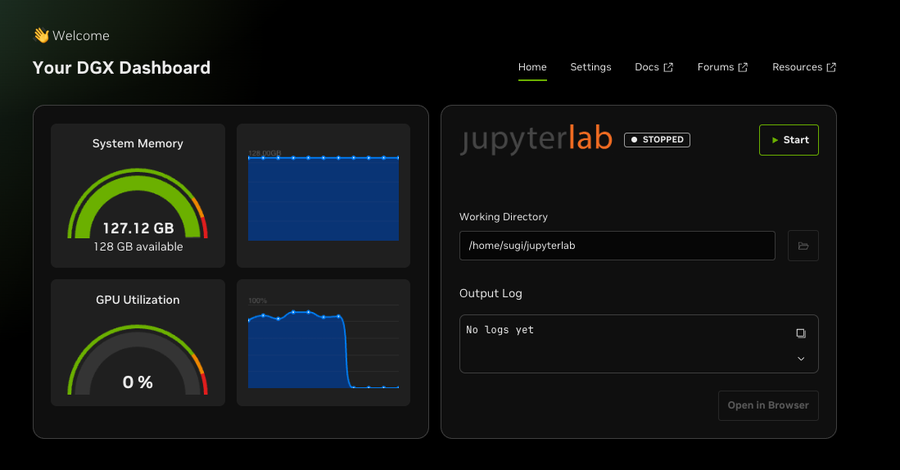
it it was the expected 67GB or so of memory and interestingly once I ran this on
the NVIDIA dashboard for this it was showing all of the memory as being
allocated, however other diagnostics make me think it was closer to the expected
67GB.Nvidia DGX Spark memory usage dashboard
So once we were at a point where we could generate text my next thought was this
generation speed feels “ok… but I guess I have no idea how fast this actually
is”.Unsurprisingly it wasn’t aware of the new DGX spark which makes perfect sense
NVIDIA Spark vs M4 Apple Silicon 128GB The DGX Spark box released on Oct 15,
currently it is Oct 24 so I am guessing there will be future releases for
software, drivers, etc that will smooth out some of the metrics and increase
token generation speed but as of week one here are some baseline metrics.
Earlier this year our team purchased M4 Macbook Pros with 128Gb of unified
memory which is quite convenient here. When I got my Macbook one of the first
things I did was download some large models and run them to see how they did.
After downloading maybe 1TB of models I haven’t bothered to do so again for
awhile since most of my work recently hasn’t been around testing those models. I
ran a series of 5 prompts through a Llama 4 model via Ollama and the initial
takeaway was “wow the M4 mac does way better”. For the early tests I was testing
shortish prompts and output, which showed pretty consistent 30+ tokens/s (tokens
per second) generation speed vs the DGX spark box’s ~16.8 tokens/s. So at a
glance it would be easy to say that the M4 Apple Silicon architecture runs away
with this test. However something interesting was that as the context length
increased the token generation speed on the M4 got slower (as expected) but the
NVIDIA one was basically constant at 16.8 tokens/s. This led me to add some
additional test where I fed the entire Pokemon Red, Blue, Yellow wikipedia page
in as context and told it to generate a long piece of text. This wikipedia page
is ~6,000 words or so and to generate an essay about the games the M4 showed a
degraded speed down to 18.81 tokens/s (38% decrease) vs the DGX Spark at 16.0
tokens/s (5% decrease). So while the M4 is still slightly faster, the DGX Spark
doesn’t show any of the speed degradation I would have expected. ### Takeaways
As of now Oct 24 the NVIDIA DGX Spark with a Llama 4 model is ~79.6% the speed
of an Apple Silicon M4 machine on generation tasks when both have 128GB of
unified RAM. However the DGX Spark doesn’t exhibit the standard degradation of
generation speed as the context length increases. Since it is still early I
expect more optimizations to be made and the speed will get faster if these
changes don’t cause the same sorts of degradation then the DGX Spark box could
be very interesting. However I expect that once the proper kernels/software is
added to the Spark ecosystem then the framework will have faster generation
speeds that will get slower with longer input/output sequences. That will
probably bring it much closer to the M4 numbers once it is more mature. Reading
through some other
blogs
I saw a good comment around how the ARM64 architecture on the DGX spark is
mature due to other devices like the Jetson boards, but the Blackwell GB10 GPU
is new and CUDA 13.0 has just been released. So this means it will take a bit of
time to catch up to more fully fleshed out ecosystems. Over time once this
Blackwell GB10 GPU ecosystem is more fleshed out I would expect to see faster
token generation speeds and then the normal performance degradation as we get
into longer input and output contexts. From a price perspective the NVIDIA Spark
box is reasonably competitive. When we got our laptops they cost $4,849 while
the Spark runs at $4000. So depending on your use case you could get access to
128GB of unified memory to run models on at a lower price at an albeit slower
speed than other options for now. I think that once the ecosystem is fleshed out
a bit more then the NVIDIA Spark could be a good option to test or host models
where you don’t need the absolute fastest response times or host a number of
smaller models leveraging the 128GB of memory. ## DeepSeek OCRI’m doing my first play through of Hollow Knight Silksong
This section was inspired by Simon Willison’s blog
here The
DeepSeek model is a 3B parameter model, my environment had an appropriate CUDA
13 setup since I had done some tests previously. Using a docker setup largely
based off of the setup that they used for their Pytorch tutorials
here. The main piece is the
docker container
nvcr.io/NVIDIA/pytorch:25.09-py3 and
then from there we can configure it as we need via a dockerfile (in the
appendix). ### Claude Code Issues Initially it had some issues finding a version
of transformers and Pytorch that would work with this pipeline. It tried Pytorch
2.7 + CUDA 13 but couldn’t find a version that was compatible with ARM64 and
CUDA so it went to Pytorch 2.9 + CUDA 13. Then similarly there was an issue with
transformers versioning; there was an import error with LlamaFlashAttention2
which was solved by moving to an older version of transformers than it tried to
use initially, so it pinned transformers==4.46.3 which solved the immediate
issues around getting it to run. After this I ran into an issue that in
retrospect Simon also ran into an issue where saved output files initially only
had whitespace. Claude raised a victory flag saying it ran the model, but when i
told it to look into the files it was confused and assumed the model hadn’t
detected anything. I pushed back that the Silksong wallpaper does indeed have
text. For that it just had to figure out the correct structure, it was just
printing out the content instead of writing it to the file we wanted. From the
wallpaper we got the following pieces of text and their detected coordinates.
This wasn’t the most complicated test, but it gets all the sections and isolates
them to the correct bounding box areas and handles the slightly odd text styles.
<|ref|>NINTENDO<|/ref|><|det|>[[160, 144, 240, 164]]<|/det|>
<|ref|>SWITCH.<|/ref|><|det|>[[24, 164, 115, 195]]<|/det|>
<|ref|>SWITCH.<|/ref|><|det|>[[160, 164, 240, 195]]<|/det|> <|ref|>HOLLOW
KNIGHT<|/ref|><|det|>[[384, 710, 600, 754]]<|/det|>
<|ref|>SILKSONG<|/ref|><|det|>[[299, 757, 699, 949]]<|/det|> ``` ### DeepSeek
OCR Takeaways This process was very smooth and took maybe 40-60 minutes.
Building off of the docker containers that I knew worked on this system made the
process easier and more repeatable. The only issues I hit were the standard
sorts of one I would expect when using new models where you have to figure out
appropriate Pytorch and transformers versions and then some oddness around how
the model was displaying data but that issue was also quickly resolved. This is
quite nice overall since a few days after a new model came out I was able to get
it running relatively painlessly on a new NVIDIA DGX Spark device. ## Llama 3.1
70B LoRA training
NVIDIA Spark page
For this I opted for a standard LoRA training run vs a full fine-tuning of the
full model. I could likely have tested larger models but this was mostly a proof
of concept to see how smooth this would mechanically work. ### Methods This test
is me applying a small dataset (2K samples) I built for a different experiment
and using it to benchmark how well this process works on the DGX Spark and for
it I took a pipeline I had built in a jupyter notebook and migrated it over to a
docker container based pipeline. For this I referenced their playbook on
[unsloth training in Pytorch](https://build.nvidia.com/spark/unsloth). The main
useful pieces were seeing how they configured their docker containers and set
everything up. Once that was done all I had to do was swap in the new custom
dataset I had built. While not super important, the dataset was one I generated
to train a small query decomposition model. The idea is that when a user submits
a query, it may or may not be well aligned to the items we actually have within
our RAG backend so the idea was to train a model to do this decomposition task
by breaking the main query down into a set of N search queries. ## Training and
inference After the standard issues around docker containers and figuring out
what versions of Pytorch play well with what the training process was
straightforward. It took ~8.5 hours to do 340 batches of size 64 through the
model (it was 10 epochs), as expected the model overfit to the problem but I was
mostly just here to see how smooth this process was. Then the model does what we
would expect on a new case, is it great? no… but that is mostly a dataset issue
for a test thing i was doing before. The model learns to take in some query,
generate a json response with a reasoning and decomposed query fields. The below
section just shows what this looks like once we parse a result. ```prompt Input:
How do I learn machine learning while working full-time as a software engineer?
Reasoning: User need combines professional education, technology field learning,
and time management for working engineers. Decomposed queries: ['machine
learning learning plans', 'full-time work balance learning', 'software engineer
education', 'time management for learning'] ``` The model was around 37GB at 4
bit quantization, and the model + training took around 74Gb of the 128 total.
This means we likely could do a larger model, I am unsure if we can fit a 200B
parameter model the way their docs claim, but I have not really been able to do
training runs using models at the 70B parameter size easily before so this was a
nice change of pace. ### Llama 70B LoRA training Takeaways Like before, this
machine is probably not the fastest way to do it, but the 128GB unified RAM does
make it much simpler to physically be able to do these sorts of tasks. Like the
idea that we can train in house adapters for a 70B parameter model without much
difficulty is pretty great. While training the peak used memory was only 74GB
out of 128Gb which means we do have a good bit of leeway to train larger models
or be more involved. Interestingly reading through that
[AIXplore](https://publish.obsidian.md/aixplore/Practical+Applications/dgx-lab-benchmarks-vs-reality-day-4#What's+Production-Ready)
article it looks like I got lucky and dodged a few bullets around issue with
inference using FP16 since I kept the model at 4 bit quantization given the
size. Another issue the authors cite is that they had to manually empty the
cache every 50 training steps. My guess is that Unsloth handles this under the
hood since it includes warnings saying `Unsloth: Will smartly offload gradients
to save VRAM!` ## Conclusions Getting early access to the NVIDIA DGX Spark has
been a fun experience to play with some interesting hardware early on in its
lifecycle. The price point seems pretty good for access to 128GB of unified
memory and once we get proper support for the ecosystem hopefully we get faster
generation and training speeds which helps round out its performance. For me it
is nice to have access to the ability to train and host some of the larger
models in house if we so chose, it helps to smooth out some of the annoyances of
LLMs and how to make use of them. So I will be looking for how we can best
utilize the DGX Spark as part of our pipelines as we move forward. ### Appendix:
### Docker File for DeepSeek OCR ``` # DeepSeek-OCR using NVIDIA PyTorch 25.09
container # Following NVIDIA DGX Spark playbook approach FROM
nvcr.io/NVIDIA/pytorch:25.09-py3 # Set environment variables ENV
DEBIAN_FRONTEND=noninteractive ENV PYTHONUNBUFFERED=1 LABEL
maintainer="DeepSeek-OCR Pipeline" LABEL description="NVIDIA PyTorch container
with DeepSeek-OCR for vision-language OCR" # PyTorch is already installed in
this container with CUDA support # Install DeepSeek-OCR specific dependencies #
NOTE: transformers 4.46.3 is required for DeepSeek-OCR compatibility RUN pip
install --no-cache-dir \ 'transformers==4.46.3' \ 'tokenizers==0.20.3' \
accelerate \ pillow \ requests \ huggingface_hub \ einops \ addict \ easydict \
matplotlib \ timm # Verify installations RUN python3 -c "import torch;
print(f'PyTorch: {torch.**version**}')" && \ python3 -c "import transformers;
print(f'Transformers: {transformers.**version**}')" && \ python3 -c "import
torch; print(f'CUDA available: {torch.cuda.is_available()}')" && \ echo "✓ All
packages installed successfully" # Set working directory WORKDIR /workspace #
Default command CMD ["/bin/bash"] ```


](/posts/week-0-nvidia-dgx-spark-experiments/image%202_hu_124442e5c55e8536.png)