Word Compiler, A Context Compiler for Long-Form Fiction
← All PostsThe problem
Writing a novel with an LLM is an exercise in frustration. You become a prompt engineer. You hand-craft system messages, copy-paste context, juggle character details across sessions, lose track of what the model “knows,” and watch prose degrade as the story outgrows the context window. Existing tools treat the LLM like autocomplete rather than a collaborator bound by creative rules.
The author’s real contributions (voice, world, narrative intent) scatter across ad hoc prompts, vanish between sessions, and teach nothing to the next generation pass.
The compiler analogy
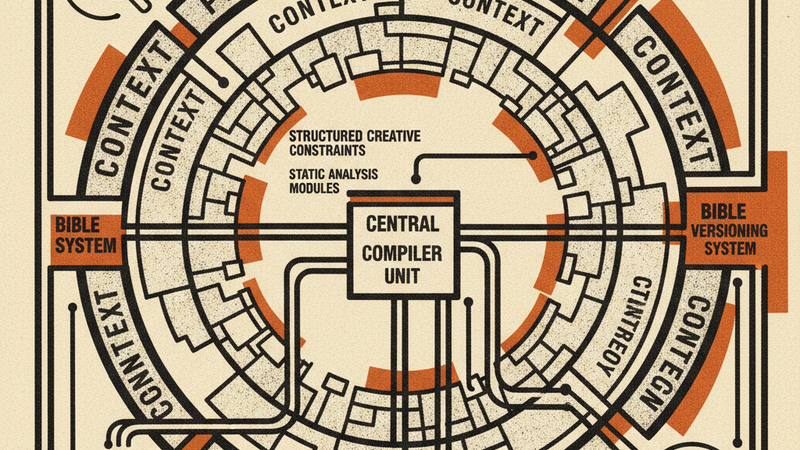
Word Compiler borrows its architecture from software compilers. A compiler reads source code, builds an intermediate representation, optimizes within constraints, and emits machine code. Word Compiler does the same thing with prose:
| Compiler concept | Word Compiler equivalent |
|---|---|
| Source code | The Bible, a structured document containing character dossiers, a style guide, locations, narrative rules, and a kill list of banned phrases |
| Intermediate representation | Narrative IR, per-scene extraction of events, character deltas, and epistemic state |
| Optimization | Budget enforcer, priority-based compression that guarantees the prompt fits the context window |
| Static analysis | Linter (pre-generation) and Auditor (post-generation) |
| Linker | Cross-scene bridging, continuity via Narrative IR character state and unresolved tensions |
| Codegen | The LLM call itself, the only async, expensive step |
The user never writes a prompt. They fill in structured fields (character dossiers, scene contracts with emotional beats, anchor lines, subtext contracts) and the compiler assembles the context payload.
What this actually solves
It solves the context window problem for long-form work.
We built a three-ring architecture that gives the LLM the right context at the right scope.
Ring 1 (the system message) carries project-level identity: voice rules, POV policy, sentence architecture, vocabulary preferences, the kill list, structural bans, positive and negative exemplars.
Ring 2 carries chapter-level continuity: the chapter arc, reader epistemic state, active setups, cumulative character states derived from prior scenes’ Narrative IR.
Ring 3 carries scene-level specifics: the scene contract, voice fingerprints for speaking characters, sensory palette, anchor lines, a continuity bridge from prior chunks or the previous scene, anti-ablation guardrails.
When the total exceeds the token budget, the compiler compresses. It strips Ring 1 first, then Ring 2, then Ring 3 as a last resort. Within each ring, it cuts non-immune sections in priority order, highest priority number first. Immune sections (the kill list, structural rules, POV policy, scene contract, voice fingerprints, anchor lines, anti-ablation) are never removed.
The default config allocates Ring 3 a minimum 60% share, and the linter warns if it drops below 40%.
A 100,000-word novel doesn’t degrade at chapter 20 the way it does when you paste the whole manuscript into a chat window. The compiler assembles exactly the context each chunk needs.
It gives you creative control without prompt engineering
The Bible is the single source of style truth, and it’s versioned. Every edit creates a new version, and a gate prevents generation against a stale one. Voice decisions, character verbal tics, structural bans, every word on the kill list. All in one document. The author specifies intent, not instructions.
Scene plans are just as precise. Each defines a narrative goal, emotional beat, desired reader effect, subtext contract (surface conversation vs. actual conversation, with an enforcement rule), anchor lines (human-authored sentences that can be marked verbatim or left as energy targets), and the failure mode to avoid. The compiler translates all of it into a prompt.
It applies static analysis and auditing to prose.
After every generation, the auditor scans the prose against the Bible for:
- Kill list violations, scanning for every word and phrase on the list, case-insensitive
- Sentence variance, flagging rhythmically flat passages where the standard deviation of sentence length falls below 3.0 words
- Paragraph length, flagging paragraphs that exceed the author’s configured maximum sentence count
- Epistemic leak detection, cross-referencing character knowledge against the Narrative IR from prior scenes. If a character mentions something they were never shown learning, it gets flagged
- Setup/payoff tracking, comparing what the scene plan said would be planted or paid off against what the IR says actually happened. At manuscript completion, any planted setup that was never resolved gets flagged
- Subtext compliance, it sends the prose and the scene’s subtext contract to a model to check whether any character says the quiet part out loud
These are the prose equivalents of linting, type checking, and integration tests. Unresolved critical audit flags block a scene from advancing through the workflow gates. Warnings and info-level flags don’t block progress, but they stay visible until the author resolves or dismisses them.
It builds voice through structured constraints.
Voice in Word Compiler is overlapping constraints compiled into every prompt. The Bible carries character-level voice fingerprints (vocabulary notes, verbal tics, metaphoric register, prohibited language, dialogue samples) and project-level style rules (positive and negative exemplars, sentence architecture, metaphoric domains, vocabulary preferences). Ring 1 assembles these into the system message. Ring 3 injects per-character voice fingerprints for every speaking character in the scene.
How the Author Stays in Charge
Every stage puts a decision in the author’s hands.
You can paste a synopsis and the system generates a draft Bible (characters, locations, tone, kill list). Or build everything from scratch. Every field is editable. The Bible belongs to you.
Scene plans include fields that only a human storyteller fills well. The subtext field captures what characters appear to discuss versus what they’re actually communicating, with an enforcement rule. Anchor lines are specific sentences the author has written that must appear verbatim. The failure mode states what to steer clear of (“Don’t telegraph the twist,” “No melodramatic dialogue”).
Generation proceeds chunk by chunk. Each scene’s target word count (author-configurable, defaulting to 800 to 1200 words) is divided across a set number of chunks. The author reviews each one and marks it accepted, edited, or rejected. Editing is where the real authorship happens. The learner is watching, analyzing the delta between what the AI wrote and what the author kept, classifying edits by type: filler cuts, tone shifts, show-don’t-tell substitutions, sensory additions.
The author resolves every audit flag by marking it actionable or dismissed. Resolution data feeds a signal-to-noise metric that tracks audit quality by category over time. Nothing is auto-fixed.
After a scene is complete, the system extracts a structured representation of what happened: events, facts introduced, facts revealed to the reader, facts withheld, character deltas, setups planted, payoffs executed, character positions, unresolved tensions. The record starts unverified. The author reviews and confirms it before it feeds cross-scene continuity.
Bible proposals from the revision learner and tuning proposals from the parameter analyzer both arrive pending until the author accepts or rejects them. The system proposes. The author disposes.
Ideas we borrowed from AI-assisted coding
We built this the way we think about code.
A code compiler transforms source into optimized machine code. The context compiler transforms structured creative intent (characters, voice rules, scene contracts) into LLM prompts. The author works with high-level abstractions and the compiler handles translation.
Pre-generation linting catches structural problems (missing voice samples, starved Ring 3, POV character not in Bible) before they become prose. Post-generation auditing catches prose problems (kill-list violations, sentence variance, subtext collapse) before the author accepts a chunk. Two systems, two moments in the pipeline. Catch defects early.
Workflow gates enforce quality discipline the way CI enforces merge discipline. You can’t mark a scene complete if unresolved critical audit flags remain, just as you can’t merge a PR with failing checks.
The Bible is versioned. Each version is stored separately, so the system can retrieve exactly which rules were in effect when a particular chunk was generated.
Just as compiler IRs enable cross-module optimization, the Narrative IR makes story content machine-readable: facts revealed, facts withheld, character knowledge deltas, setups planted, payoffs executed. That data feeds cross-scene analysis and reader-state simulation.
The budget enforcer works like a register allocator. It operates within a hard constraint (the context window minus reserved output tokens) and makes tradeoffs about which ring sections to drop, and in what order. Ring 1 compresses first, then Ring 2, then Ring 3. Immune sections (kill list, scene contract, voice fingerprints) are never cut.
The revision learner infers preferences from edits. It diffs generated text against the accepted version at sentence level, classifies each change, groups recurring patterns, and proposes Bible updates when confidence crosses a threshold. No configuration. It watches what you do and proposes changes.
The audit system tracks its own accuracy. Every resolved flag is marked actionable or dismissed, and the ratio (actionable divided by total decided) tells the author whether the auditor is helping or crying wolf.
The bet is that the same feedback loops, quality gates, and compilation discipline that made AI-assisted coding feel like collaboration rather than a coin flip can work for prose. The author keeps creative authority. The machine handles assembly, constraints, and pattern detection.
Try it
Word Compiler is open source and runs locally. Clone the repo, pnpm dev:all, and you’re up. It uses the Anthropic API for generation, so you’ll need a key.
It’s early. There are rough edges and open questions, which is the point. But the core loop works: Bible in, compiled context out, prose generated chunk by chunk with auditing and learning after each pass. If you’re writing fiction with AI and you’re tired of fighting the context window, we’d like to know what you think.